Statistical Models#
Will this Animal be Adopted?#
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
import statsmodels.api as sm
import statsmodels.formula.api as smf
from sklearn.metrics import confusion_matrix
from statsmodels.stats.outliers_influence import variance_inflation_factor
from sheltertools.utils import *
import random
random.seed(159)
shelter_data = pd.read_csv('./data/Animal_Shelter_Data.csv')
shelter_data.dropna(subset=['Size'], inplace=True)
shelter_data.rename(columns={'Intake Subtype': 'Intake_Subtype',
'Intake Type': 'Intake_Type',
'Intake Condition': 'Intake_Condition'}, inplace=True)
# Create a new column named Adopted, and assign a value of 0 or 1
# to indicate whether each animal has been adopted or not.
shelter_data['Adopted'] = (shelter_data['Outcome Type'] == 'ADOPTION').astype(int)
shelter_data['Intake Year'] = shelter_data['Intake Date'].apply(lambda x: x[-4:])
#Split the data into test and train
shelter_train, shelter_test = train_test_split(shelter_data, test_size=0.3, random_state=159)
shelter_train.shape, shelter_test.shape
((17481, 26), (7492, 26))
import statsmodels.formula.api as smf
logreg = smf.logit(formula = 'Adopted ~ Type + Sex + Size + Intake_Type + Intake_Condition',
data = shelter_train).fit()
print(logreg.summary())
Warning: Maximum number of iterations has been exceeded.
Current function value: 0.357273
Iterations: 35
Logit Regression Results
==============================================================================
Dep. Variable: Adopted No. Observations: 17481
Model: Logit Df Residuals: 17457
Method: MLE Df Model: 23
Date: Thu, 11 May 2023 Pseudo R-squ.: 0.4094
Time: 05:44:30 Log-Likelihood: -6245.5
converged: False LL-Null: -10575.
Covariance Type: nonrobust LLR p-value: 0.000
============================================================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------------------------------------
Intercept -0.2155 0.201 -1.072 0.284 -0.610 0.179
Type[T.DOG] -0.2597 0.069 -3.740 0.000 -0.396 -0.124
Type[T.OTHER] 2.1649 0.132 16.347 0.000 1.905 2.424
Sex[T.Male] -0.3421 0.166 -2.064 0.039 -0.667 -0.017
Sex[T.Neutered] 3.4818 0.131 26.629 0.000 3.225 3.738
Sex[T.Spayed] 3.6436 0.132 27.655 0.000 3.385 3.902
Sex[T.Unknown] -0.8231 0.192 -4.298 0.000 -1.198 -0.448
Size[T.LARGE] -2.3318 0.111 -21.093 0.000 -2.549 -2.115
Size[T.MED] -1.9292 0.107 -17.972 0.000 -2.140 -1.719
Size[T.PUPPY] 0.0186 0.154 0.121 0.904 -0.284 0.321
Size[T.SMALL] -1.5469 0.081 -19.133 0.000 -1.705 -1.388
Size[T.TOY] -1.3876 0.129 -10.746 0.000 -1.641 -1.134
Size[T.X-LRG] -2.8595 0.287 -9.963 0.000 -3.422 -2.297
Intake_Type[T.BORN HERE] -18.5356 8192.129 -0.002 0.998 -1.61e+04 1.6e+04
Intake_Type[T.CONFISCATE] -2.4406 0.175 -13.907 0.000 -2.785 -2.097
Intake_Type[T.OS APPT] -15.0138 3346.556 -0.004 0.996 -6574.143 6544.115
Intake_Type[T.OWNER SURRENDER] -0.8415 0.157 -5.360 0.000 -1.149 -0.534
Intake_Type[T.QUARANTINE] -3.2438 0.300 -10.818 0.000 -3.832 -2.656
Intake_Type[T.STRAY] -1.6970 0.148 -11.465 0.000 -1.987 -1.407
Intake_Type[T.TRANSFER] -1.0886 0.205 -5.298 0.000 -1.491 -0.686
Intake_Condition[T.TREATABLE/MANAGEABLE] -0.5956 0.091 -6.543 0.000 -0.774 -0.417
Intake_Condition[T.TREATABLE/REHAB] 0.3818 0.077 4.954 0.000 0.231 0.533
Intake_Condition[T.UNKNOWN] -1.3646 0.063 -21.801 0.000 -1.487 -1.242
Intake_Condition[T.UNTREATABLE] -4.3279 0.360 -12.012 0.000 -5.034 -3.622
============================================================================================================
/srv/conda/envs/notebook/lib/python3.10/site-packages/statsmodels/base/model.py:604: ConvergenceWarning: Maximum Likelihood optimization failed to converge. Check mle_retvals
warnings.warn("Maximum Likelihood optimization failed to "
# Predicting the probability of adopted
y_prob = logreg.predict(shelter_test)
# Predicting the label: 0 or 1?
y_pred = pd.Series([1 if x > 1/2 else 0 for x in y_prob], index=y_prob.index)
from sklearn.metrics import confusion_matrix
y_test = shelter_test['Adopted']
cm = confusion_matrix(y_test, y_pred)
print ("Confusion Matrix : \n", cm)
Confusion Matrix :
[[4820 460]
[ 809 1403]]
TN, FP, FN, TP = cm.ravel()
# What is the Accuracy?
acc= (TN + TP) / sum(cm.ravel())
print('Accuracy is: %.4f' %acc)
# What is the True Positive Rate ?
TPR_logit = TP/(TP+FN)
print('TPR is: %.4f' % TPR_logit)
# What is the False Positive rate ?
FPR_logit = FP/(FP+TN)
print('FPR is: %.4f' % FPR_logit)
Accuracy is: 0.8306
TPR is: 0.6343
FPR is: 0.0871
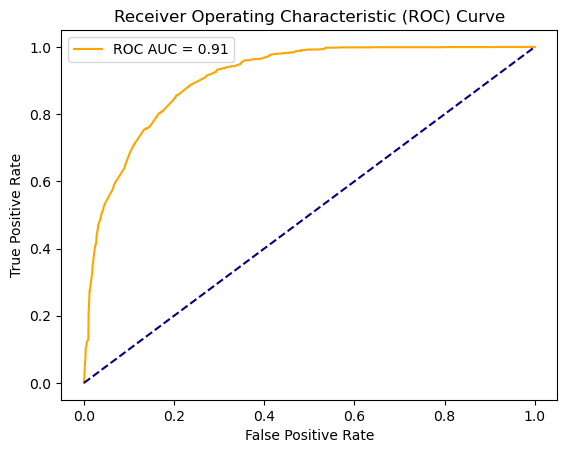
# Plotting the ROC Curve
from sklearn.metrics import roc_curve, roc_auc_score
fpr, tpr, thresholds = roc_curve(y_test, y_prob)
roc_auc = roc_auc_score(y_test, y_prob)
plt.plot(fpr, tpr, color='orange', label=f'ROC AUC = {roc_auc:.2f}')
plt.plot([0, 1], [0, 1], color='navy', linestyle='--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.legend()
plt.show()
# Plotting precision and recall rates using different decision boundaries
from sklearn.metrics import precision_score, recall_score
boundary_precisions = []
boundary_recalls = []
for b in np.arange (0.1, 0.9, 0.01) :
boundary_predictions = (y_prob >= b).astype(int)
boundary_precisions.append(precision_score(y_test, boundary_predictions) * 100)
boundary_recalls.append(recall_score(y_test, boundary_predictions) * 100)
plt.plot(np.arange(0.1, 0.9, 0.01), boundary_precisions, color='blue', linestyle='--', alpha=0.5, label='p')
plt.plot(np.arange(0.1, 0.9, 0.01), boundary_recalls, color='red', linestyle='--', alpha=0.5, label='r')
plt.xlabel('Decision Boundaries')
plt.ylabel('Score')
plt.title( 'Precision and Recall for Different Decision Boundaries')
plt.legend(loc='lower left')
plt.grid(True)
plt.show()
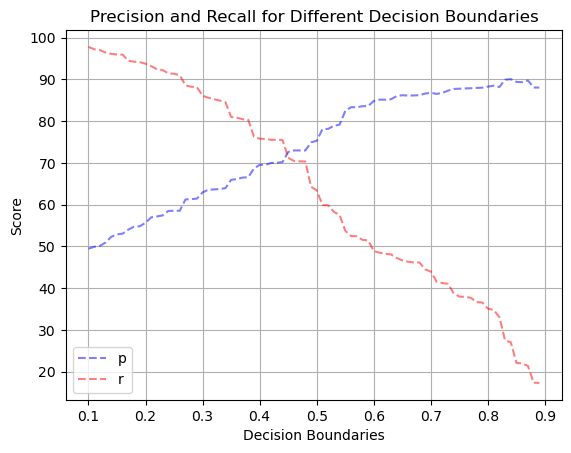
Our model predicting whether or not an animal will be adopted performed adequately. It achieved an accuracy of 83%, true positive rate of 63%, and a 9% false positive rate when using a standard 0.5 decision boundary. The ROC-AUC score was 0.91. When plotting the precision and recall rates using different decision boundaries, both lines intersected around 72%
How Many Days Before Adoption?#
### filtering on animals that are ultimately adopted
adopted_all = shelter_data[shelter_data['Outcome Type'] == 'ADOPTION']
### keeping only relevant columns
adopted = adopted_all[['Type', 'Breed', 'Color', 'Sex', 'Size', 'Date Of Birth', 'Intake Date','Days in Shelter',
'Intake_Type', 'Intake_Subtype', 'Intake_Condition', 'Intake Jurisdiction', 'Location',
'Intake Year']]
adopted = adopted.reset_index(drop=True)
### creating a feature for animal age at intake time
adopted = adopted[~adopted['Date Of Birth'].isna()]
adopted = adopted.reset_index(drop=True)
adopted['age'] = (pd.to_datetime(adopted['Intake Date'], format='%m/%d/%Y') - pd.to_datetime(adopted['Date Of Birth'],
format='%m/%d/%Y')).dt.days
adopted = adopted.drop(columns=['Intake Date', 'Date Of Birth'])
adopted = adopted.fillna('nan')
### filtering on animals that are ultimately adopted
adopted_all = shelter_data[shelter_data['Outcome Type'] == 'ADOPTION']
### keeping only relevant columns
adopted = adopted_all[['Type', 'Breed', 'Color', 'Sex', 'Size', 'Date Of Birth', 'Intake Date','Days in Shelter',
'Intake_Type', 'Intake_Subtype', 'Intake_Condition', 'Intake Jurisdiction', 'Location',
'Intake Year']]
adopted = adopted.reset_index(drop=True)
### creating a feature for animal age at intake time
adopted = adopted[~adopted['Date Of Birth'].isna()]
adopted = adopted.reset_index(drop=True)
adopted['age'] = (pd.to_datetime(adopted['Intake Date'], format='%m/%d/%Y') - pd.to_datetime(adopted['Date Of Birth'],
format='%m/%d/%Y')).dt.days
adopted = adopted.drop(columns=['Intake Date', 'Date Of Birth'])
adopted = adopted.fillna('nan')
adopted_all.columns
Index(['Name', 'Type', 'Breed', 'Color', 'Sex', 'Size', 'Date Of Birth',
'Impound Number', 'Kennel Number', 'Animal ID', 'Intake Date',
'Outcome Date', 'Days in Shelter', 'Intake_Type', 'Intake_Subtype',
'Outcome Type', 'Outcome Subtype', 'Intake_Condition',
'Outcome Condition', 'Intake Jurisdiction', 'Outcome Jurisdiction',
'Outcome Zip Code', 'Location', 'Count', 'Adopted', 'Intake Year'],
dtype='object')
adopted['log_days'] = np.log1p(adopted['Days in Shelter'])
adopted_filtered = adopted[adopted['Days in Shelter']< 200]
!pip install catboost -q
### test train split
from catboost import CatBoostRegressor
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
X_train, X_test, y_train, y_test = train_test_split(adopted_filtered.drop(['Days in Shelter', 'log_days'], axis=1),
adopted_filtered['log_days'], test_size=0.2, random_state=42)
model = CatBoostRegressor(cat_features=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10], loss_function='MAE', verbose=500,
depth=9, iterations=1500, learning_rate=0.05)
fitted_result = model.fit(X_train, y_train)
predictions = model.predict(X_test)
fitted_result
0: learn: 0.6458547 total: 69.3ms remaining: 1m 43s
500: learn: 0.3103670 total: 11.6s remaining: 23.2s
1000: learn: 0.2503310 total: 23.1s remaining: 11.5s
1499: learn: 0.2160745 total: 34.2s remaining: 0us
<catboost.core.CatBoostRegressor at 0x7fa2e9222770>
import pickle
# Save the model
with open('computation_results/' + 'CatBoostRegressor.pickle', 'wb') as f:
pickle.dump(model, f)
# Save the predictions
with open('computation_results/' + 'CatPredictions.pickle', 'wb') as f:
pickle.dump(predictions, f)
with open('computation_results/' + 'CatFittedResult.pickle', 'wb') as f:
pickle.dump(fitted_result, f)
x = np.linspace(0, 8, 100)
y = x
plt.plot(x, y, color='red');
plt.scatter(x=y_test, y=predictions);
plt.show()
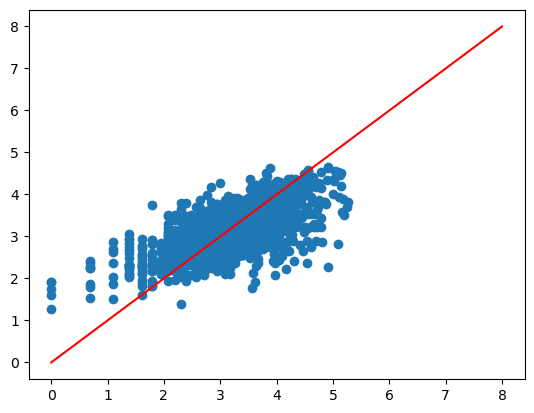
from sklearn.metrics import mean_squared_error
from sklearn.metrics import r2_score
unlog_pred = np.expm1(predictions)
unlog_actual = np.expm1(y_test)
rmse = mean_squared_error(unlog_actual, unlog_pred, squared=False)
r2 = r2_score(y_test, predictions)
print("Testing performance")
print('RMSE: {:.2f}'.format(rmse))
print('R2: {:.2f}'.format(r2))
Testing performance
RMSE: 22.60
R2: 0.48
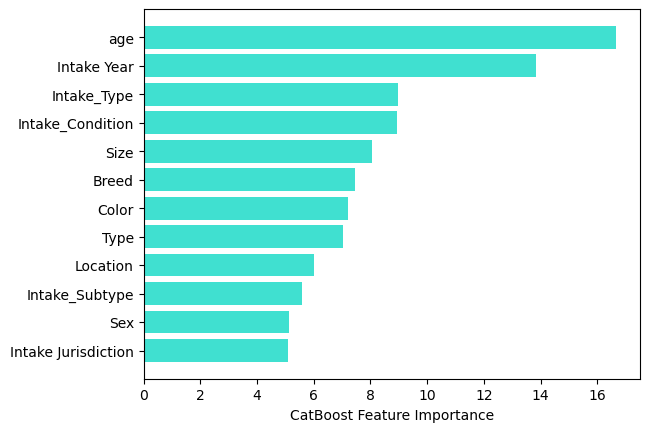
sorted_feature_importance = model.feature_importances_.argsort()
plt.barh(X_train.columns[sorted_feature_importance],
model.feature_importances_[sorted_feature_importance],
color='turquoise')
plt.xlabel("CatBoost Feature Importance");
Our model predicting the number of days before adoption did not perform very well. We transformed the target values as it followed an exponential distribution, but the model still did not perform very well. The RMSE was 22.6 days, and the R squared value was quite low, at 0.36.
But the feature importances for the CatBoost were help. It tells us that Age and Intake yere were the top 2 most important features when performing the regression.